Tuning Your Lucene Index for AEM
How to tune the Lucene index within AEM is a multistep process. Learn what you need to do to optimise your index.

The index is a core component and one that should be quick in answering any queries you fire at it. In many cases, it also grows significantly and sometimes it’s unclear why it is growing or slow. How to tune the Lucene index within AEM is a multi step process, which is briefly described in this blog article. Additionally, we will look at query analysis and traversals, and how to mitigate them to ensure that queries run fast.
When it comes to running an AEM instance in production, the index is always present. Adobe recommends some steps to tune the index further. Some are listed below, but also further extended information and documentation can be found, as the steps may not always be clear. Before trying anything like this on a production instance, make sure you do the testing on an exact copy, as this allows you to gather important information on how long the tasks take and also permits you to calculate for downtimes properly. If you are doing the tuning on a publish instance and have multiple ones to do this on, and you are running in a cloud or cloud-like infrastructure with fast snapshot capability, I recommend that you perform this on one publish, buffer the replication nodes temporarily for the others, and clone the instance. This will save much time, and in the end, you will achieve a much more equal setup.
Index tuning
Details on the functionality and architecture of the index can be found here
Open/system/console/configMgr/org.apache.jackrabbit.oak.plugins.index.lucene.LuceneIndexProviderService and
- Enable CopyOnRead
- Enable CopyOnWrite
- Enable Prefetch Index Files
- Increase the thread count (5 is the default, suggested is 20)
To check if the index is working properly
- Tail the error log and ensure the indexing is running
- After the above settings are applied, ensure that the index folder is created and being filled
- Check the following mbeans for progress
org.apache.jackrabbit.oak: "IndexCopier support statistics" ("IndexCopierStats")
org.apache.jackrabbit.oak: "async" ("IndexStats")
org.apache.jackrabbit.oak: "Lucene Index statistics" ("LuceneIndex")
The Lucene index statistics will start showing separate indexes once the initial indexing is finished.
Index tuning
In many cases traversals can occur if an index is not deemed to be useful to use. This can be quite a performance killer and, therefore, it is advisable to create custom indexes when needed. A great tool to use is the index generator. Simply create an index configuration from your xpath query and deploy it.
Removing specific things to not index
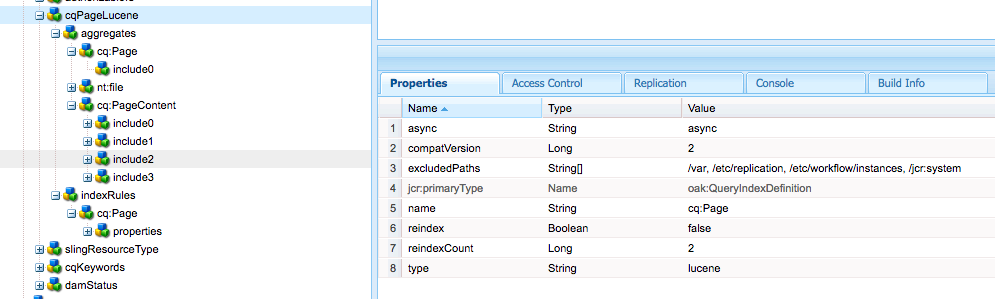
You can set a property on an index node as follows:
<i>excludedPaths="[/var,/etc/replication,/etc/workflow/instances,/jcr:system]"</i>
This can be set on the Lucene or also the cqPageLucene index.
Additionally, ensure the value rep:Toke n is added to the declaringNodeTypes properties (multi string property) for the nodetype index.
Checking your index config for duplicate aggregates
Double check your index config. Especially if there are duplicates for aggregation, there is a chance that this is wrong. The root cause for this misconfiguration at this time is unclear, but removing them and changing it to default behaviour reduces the size drastically.
Bad configuration
- cqPageLucene<br>
- aggregates<br>
- include0 - path = jcr:content<br>
- include1 - path = jcr:content/*<br>
- include2 - path = jcr:content/*/*<br>
- include3 - path = jcr:content/*/*/*<br>
- include4 - path = jcr:content/*/*/*/*<br>
- nt:file<br>
- include0<br>
- cq:PageContent<br>
- include0 - path = *<br>
- include1 - path = */*<br>
- include2 - path = */*/*<br>
- include3 - path = */*/*/*
Good configuration
- cqPageLucene<br>
- aggregates<br>
- include0 - path = jcr:content<br>
- nt:file<br>
- include0<br>
- cq:PageContent<br>
- include0 - path = *<br>
- include1 - path = */*<br>
- include2 - path = */*/*<br>
- include3 - path = */*/*/*
Apply a tika config
Below is a sample index config which applies many exclusions:
<properties>
<parsers>
<parser class="org.apache.tika.parser.EmptyParser">
<!-- Disable package extraction as it's too resource-intensive -->
<mime>application/x-archive</mime>
<mime>application/x-bzip</mime>
<mime>application/x-bzip2</mime>
<mime>application/x-cpio</mime>
<mime>application/x-gtar</mime>
<mime>application/x-gzip</mime>
<mime>application/x-tar</mime>
<mime>application/zip</mime>
<!-- Disable image extraction as there's no text to be found -->
<mime>image/bmp</mime>
<mime>image/gif</mime>
<mime>image/jpeg</mime>
<mime>image/png</mime>
<mime>image/tiff</mime>
<mime>image/vnd.wap.wbmp</mime>
<mime>image/x-icon</mime>
<mime>image/x-psd</mime>
<mime>image/x-xcf</mime>
<!-- Disable Office -->
<mime>application/pdf</mime>
<mime>application/vnd.openxmlformats-officedocument.spreadsheetml.sheet</mime>
<mime>application/vnd.ms-excel.sheet.macroenabled.12</mime>
<mime>application/vnd.openxmlformats-officedocument.spreadsheetml.template</mime>
<mime>application/vnd.ms-excel.template.macroenabled.12</mime>
<mime>application/vnd.ms-excel.addin.macroenabled.12</mime>
<mime>application/vnd.ms-excel</mime>
<mime>application/vnd.ms-excel.sheet.binary.macroenabled.12</mime>
<!-- Media -->
<mime>audio/aac</mime>
<mime>audio/mp4</mime>
<mime>audio/mpeg</mime>
<mime>audio/ogg</mime>
<mime>audio/wav</mime>
<mime>audio/webm</mime>
<mime>video/mp4</mime>
<mime>video/ogg</mime>
<mime>video/webm</mime>
</parser>
</parsers>
</properties>
The configuration needs to be created as detailed on jackrabbit.apache.org as a node beneath the index node which contains the config.xml. Additionally, aemstuff.com may give some hints as well.
Recreating the index with tuned parameters
- Ensure you have a backup (no joke!)
- Configure the above tuning options with tika config and exclusions.
- Check the index size before on the file system or via JMX within the Lucene Index statistics.
- Stop AEM.
- Run an offline compaction (detailed in a previous article).
- Run a datastore garbage collection (detailed in Adobe data storage garbage collection).
- Delete all the files beneath your ../crx-quickstart/repository/index/ directory.
- Start AEM and watch the logs. If the reindex doesn’t trigger, you should set the re-index property to true (detailed in Adobe best practices for queries and indexing).
- Initially the log can be fairly quiet as the copying is taking place, so it is better to watch the filesystem during this time.
- After a while, the regular indexing will start.
- Once it is completed, stop AEM.
- Run an offline compaction.
- Run a datastore garbage collection.
- Delete all the files beneath the crx-quickstart/repository/index/ directory.
- Start AEM and watch the logs. Initially the log can be fairly quiet as the copying is taking place of the newly created index. The size should be smaller afterwards depending on what adjustments were made.
- Once it is completed, AEM is back up and running.
- Just because it was so nice, you can run another tar compaction and then datastore garbage collection approximately 24h after the indexing finished completely - unless it is run, the old index will be kept in the datastore simply using up space even though it is not used anymore. By default, a datastore garbage collection has a max deleted time of 24h.
- Check the index size after, on the file system or via JMX within the Lucene Index statistics, and compare to details noted below step 3
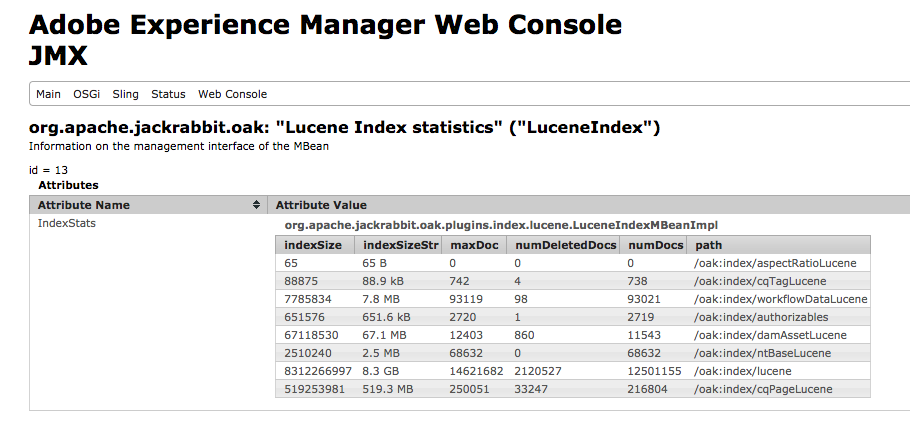
When the CopyOnRead is enabled, it only gets extended but never reduced. This is the reason why a deletion of the index on the file system is needed, so the tuned index can be copied to disk.
To reduce size of the Lucene index, the above steps must be followed including the adjusted tika config. This is time consuming and possibly, if you want to reduce the size of the index on the filesystem for a publish, it may be easier to simply disable the CopyOnRead and CopyOnWrite functionality. Check with your architect if the indexes are heavily used on the publish side or not before!
JVM Options for ensuring smooth operation
The following JVM parameters have shown much more stable performance on production systems. Ensure that these JVM parameters are in the AEM start script to prevent expensive queries from overloading the systems.
- Doak.queryLimitInMemory=500000 (see also the Oak documentation)
- Doak.queryLimitReads=100000 (see also the Oak documentation)
- Dupdate.limit=250000
- Doak.fastQuerySize=true
Conclusion
There are many things to look out for when operating an AEM instance. Not only regular maintenance tasks like a Datastore Garbage Collection or others as detailed in a previous article are important. Tar compactions are the key to reducing repository growth. Datastore garbage collections after a compaction yield the best results in reducing the datastore size. Also as noted above, optimizing your Lucene index is a good solution to further reducing the resource footprint. Additionally, it does make sense to disable specific configurations like the CopyOnRead or CopyOnWrite where they are not needed, for example, on Publish instances where search is not leveraged much.
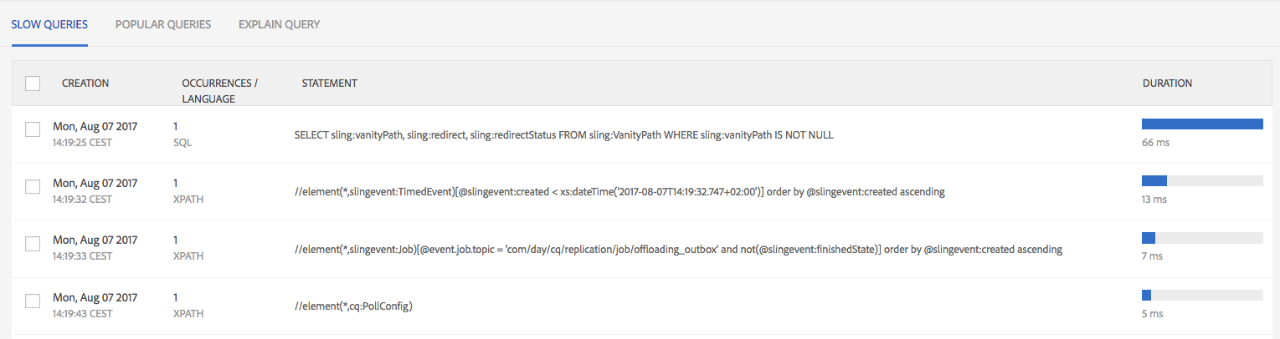
Other great resources for index optimizations or finding out why queries don’t work as they should are contained in the ACS tools, for example, the index manager. as well as the query explainer.
References
Adobe Experience Manager / Performance tuning tips | 6.x