Secure Document Search: what it is, and how Netcentric implemented it
Secure Document Search is relevant, yet in many cases, a poorly understood topic. Get ahead and learn about its use cases, implementation and architecture.

Over the last few years, the Netcentrics AEM Connector has grown a lot. We've added more customization options and new features to help our clients satisfy even more of their use cases. Recently, we decided to implement Secure Document Search for our release 3.0. During the analysis process, we discovered that there is definitely a right way and a wrong way to do it. That is why this post was put together. We want to share our expertise, work (and headaches) with you. This post starts by covering security architectures, methods and trade-offs, then it gets into specifics on how Netcentric implemented its solution.
But first, what is Secure Document Search and what do we want to achieve with it?
We want each user to see only a group of documents, the ones the user has read access to.
In general, we want the following features:
- If the user does not have read access to a document, it must not show up in the search results at all.
- The total count of documents shown for the query has to be correct.
- Facet counts shown can’t be estimates, the numbers shown have to be correct.
- The process needs to be fast, or at least, quite fast.
- We want to achieve all that without creating side effects.
Why Secure Document Search that challenging?
Secure Document Search is a hard topic because a project could be using many different content sources. That also means that there could be a many different access methods and security models involved. In other words, this world is full of special cases.
Netcentric works with Adobe Adobe Experience Manager. It means that our content store is most likely to be a JCR repository, using ACLs to manage permissions.
Access Control List (ACL)
It is a list of users and groups, and the permissions that each of them has relative to a document. One quick example:
SearchTeam
memberOf: NetcentricEmployees, everyone
path: /home/groups/H/HsiBOXSHqH3LP9f8m5q9
isGroup: 'true'
Group Membership
Users are members of groups, and groups are given read access to documents. Also, groups can be members of other groups, and those groups could be members of other groups, creating a nested inferno of groups belonging to groups.

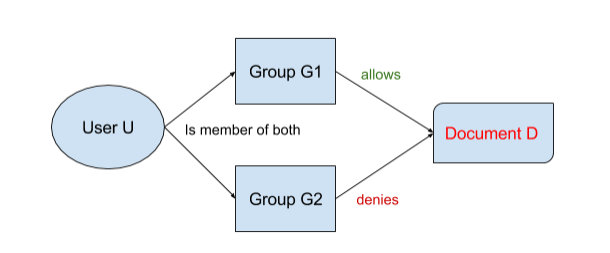
Deny
Usually permissions are positive - user U belongs to group G and can read document D. But, we could also have the opposite. Users and groups can be denied access to a document. Also both things, deny and allow, could happen at the same time, in that case, deny would prevail.
Solving the problem
Now that we know what we want to achieve and why it is hard to do it, we can talk about the right and wrong approaches to solving the problem. There are basically two approaches:
- Modifying the query before it reaches the search engine, so that the engine gives back only the results we are interested in. We call this early binding.
- Going through the results produced by the engine and manually removing some of them. This mess is called late binding
Early Binding, in a nutshell
Early binding is the process of modifying the query before it reaches the search engine, adding information that the engine will use to filter out some potential results, and only return those that the user has read access to. If we represent this idea with boxes:
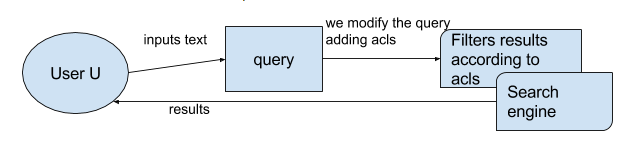
For example, we have the user: ‘Gary Murray’, he is member of ‘Netcentric employees’, and ‘Search team’. Now let’s say that he queries ‘FC Barcelona’. We will modify his query to be something like:
(FC Barcelona) AND allowACLs:(garymurray OR NetcentricEmployees OR SearchTeam)
The query will return us only documents whose allowAcl field contains either the user or one of his groups, (obviously the documents also need to contain the searched text). More on that allowAcl field later.
This is a good strategy because, let’s use a bullet list here:
- The information needed to filter the query is added to the query itself. It feels like the natural thing to do, and it should be easy to implement.
- The search engine will do the filtering for us, we can be sure that it will do it faster than what we could possibly do it. Since the filtering happens as early as possible, this approach will be the fastest one, for sure.
- The engine will return only the valid documents. We will not need to change, modify or remove any of those documents, hence the counts and facets calculated by the engine will be correct.
Drawbacks? Of course:
Earlier we mentioned the allowAcl field. That is something we need to index for each document, and it might require a lot of hard work. Also, ACLs are constantly changing, and we need to keep the index updated. This could mean having to reindex the document for the changes in its properties to take effect.
Late Binding, in a nutshell
With this approach the query is not modified before reaching the search engine. The engine will do a normal search, and return all the documents that contain the searched text. After that, the results need to be processed. The ones that are not readable for the user are discarded from the final result set presented to the user. Again, let us use some boxes.
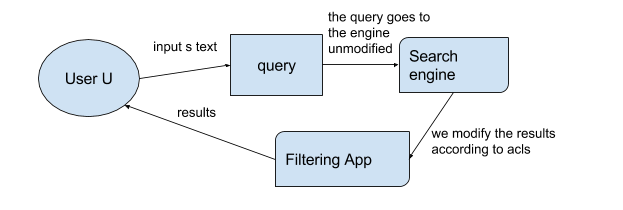
If you remember, we had a user: ‘Gary Murray’, who is member of a couple of groups: ‘Search team’ and ‘Netcentric Employees’, and he searches for ‘FC Barcelona’.
If we use the Late Binding, the query goes to the engine, and the documents containing the searched text are returned. Then we process each and every one of those results, we ask the content source: Dude, does this user have permission to see this document? (That’d be an HTTP GET request by the way.)
Good things about Late Binding:
- We do not need to index the ACLs for each document, (that allowAcl field we mentioned before) all we need to do is ask the content store if this user can see this document. Since we don’t need to index ACLs, we also don’t need to reindex them when they change.
Things that are not so good about Late Binding:
- The process could be extremely slow, and could probably mean a huge number of HTTP requests to check on permissions (Dude, does this user have permission to see this document?). Is your infrastructure ready to handle that extra overhead? Yeah, I thought so… Get ready to scale up.
Counts will be wrong. The engine does its calculations based on its result set. However, since we are going to remove documents from that list after the calculations have happened, the counts and facets calculated by the engine will not be correct anymore. We could have very good estimations of counts and facets. But even very good estimations are not fully accurate.
- Pagination problems: this one is quite obvious, if we only have an estimation of the number of results, there is no way to properly paginate the results.
As we can see, Early Binding is the way to go. So let’s talk about it in some more detail.
Architecture
This is a general overview of the architecture Netcentric used when implementing Early Binding for its AEM Connector, it’s a big and complex diagram, so pay attention!

We can divide the process in three separate blocks: indexing acls (remember our good old friend the allowAcl field), here represented in green, managing an app to provide those user acls (represented in orange) and modifying the query to include user acls (represented in blue).
Indexing ACLs
Each time we index a document, we need to add the allowAcl property to it. This property will contain the list of groups and users that have read access to the document. But getting the ACLs of a document is a process highly dependent on the content store where the documents live in. If we look at Netcentrics case, the AEM environment and the JCR repository make it reasonably easy for us:
In an AEM application, changes in permissions can be performed only in a few spots, by placing some event listeners in some clever locations, we are able to keep track of changes in permissions. When a change in a permission of a document is detected, we essentially recalculate its allow and deny ACLs and perform a reindex of the document.
The minor details of the implementation of this process are very much out of the scope of this article, so let’s move on!
The filtering app
The permissions each user has will change frequently, the filtering app is in charge of keeping an updated record of the permissions each user has. To achieve this, the filtering app will periodically request a file with the ACL information of the whole system to the Permission-extractor module (part of the AEM Connector). Once the extractor gives the file to the filtering app, the file will be parsed, the groups will be expanded, and the new permissions for each user (if any) will be saved.
At this point, you might be wondering something like: the groups will be expanded... What is that mean?
Let’s say I am a member of two groups: A and B. That means → Andres is member of [ A, B ]
Ok, fair enough, but remember that groups can be members of other groups. Now let’s say that group A is member of both group C and D. Also, Group C is member of group D. Giving us the following acl lists:
Andres is member of A, B
A is member of C, D
C is member of D
As you can easily see, we have a nested structure of group memberships, and we need to expand that structure.
After a simple recursive algorithm, we have the result of the group expansion in this example:
Andres is member of A, B, C, D
You might also be thinking about that extractor thing: the extractor gives the file to the filtering app. How does it get that system ACL file in the first place?
The extractor relies on Netcentric's ACL tool to generate the file with the permissions of the system. The ACL tool is an awesome open source project that can be found here.
Modifying the query
When the user queries a text the search index triggers a query pipeline. It will have a number of steps, for example, adding default query params, authenticating the query, etc. One of those steps will be responsible for adding document-level security to the query. It’ll do this by calling the filtering app to get the permissions of the user doing the query. And then it will add the results of that call to the query, before sending the final query to the search index.
What you now know about Secure Document Search
In this article we have talked about all the major building blocks involved in Secure Document Search. What we want to achieve, why is it a complicated problem, late binding vs early binding, a general overview of architecture, and some implementation details.
As you can see, this is not an easy topic. Solutions depend heavily on project specifics. There are a lot of different types of ACLs and content stores. A good solution requires very good error handling and the whole system needs to be highly available at all times, etc.
To conclude, I just want to thank you very much for making it to the end :)
I truly hope this read wasn't too boring, and I hope it helps you understand Secure Document Search a little bit better.